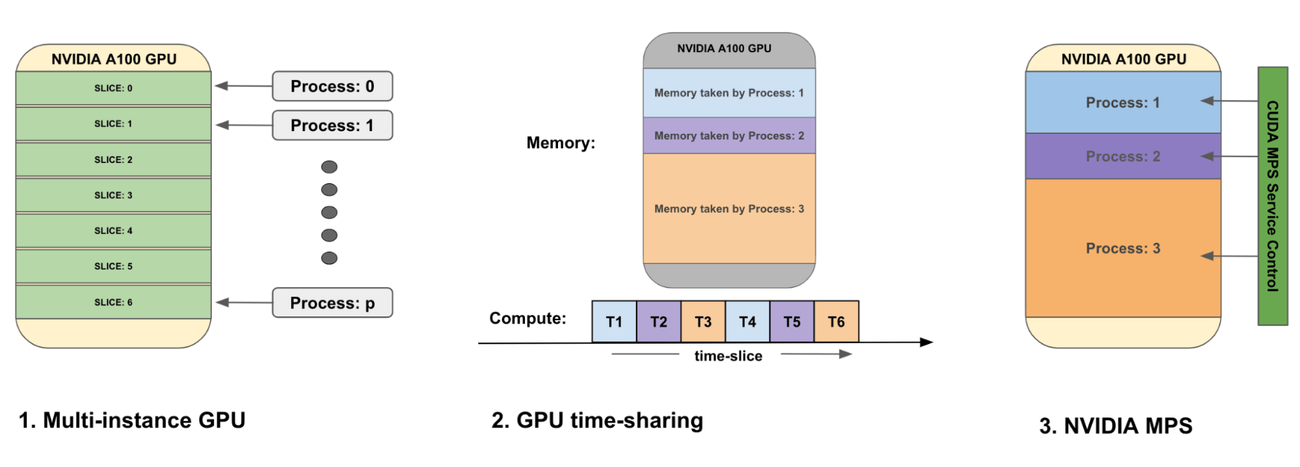
Tối ưu hóa mã giúp tăng tốc từng mô-đun trong pipeline, nhưng để đạt hiệu suất cao nhất, cần xem xét toàn bộ quy trình. Nhiều pipeline tạo ảnh đa bước sử dụng nhiều mô hình nối tiếp nhau (như sampler, decoder, mô hình nhúng ảnh/văn bản) trên cùng một container với một GPU duy nhất.
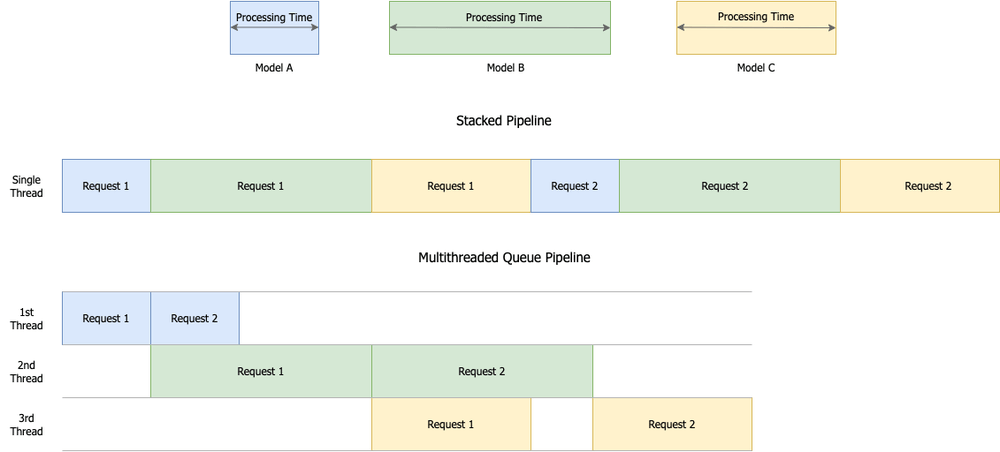
Trong pipeline dựa trên Diffusion, các mô hình như decoder có độ phức tạp tính toán cao hơn đáng kể so với mô hình nhúng, dẫn đến thời gian xử lý lâu hơn và có thể gây tắc nghẽn. Để tối ưu hóa GPU và giảm bottleneck, bạn có thể áp dụng phương pháp xếp hàng đa luồng (multi-threaded queue) để lập lịch và thực thi tác vụ hiệu quả hơn. Cách này cho phép các giai đoạn pipeline chạy song song trên cùng một GPU, giúp xử lý nhiều yêu cầu đồng thời, giảm thời gian GPU chờ và tối đa hóa tài nguyên.
Ngoài ra, việc duy trì tensor trên cùng một GPU trong suốt quá trình xử lý sẽ giảm bớt chi phí chuyển dữ liệu giữa CPU và GPU, từ đó tăng hiệu suất và tối ưu chi phí vận hành.