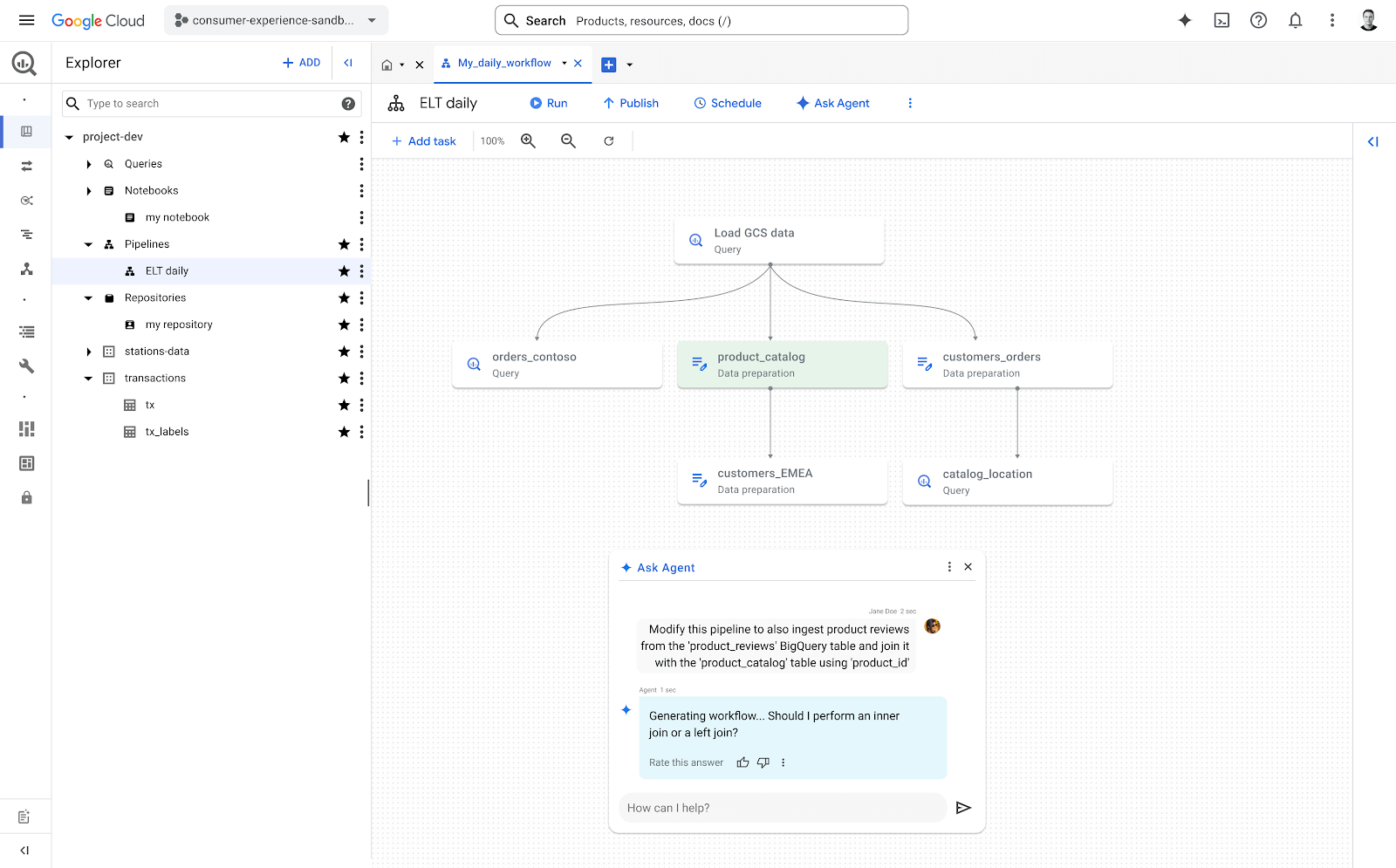
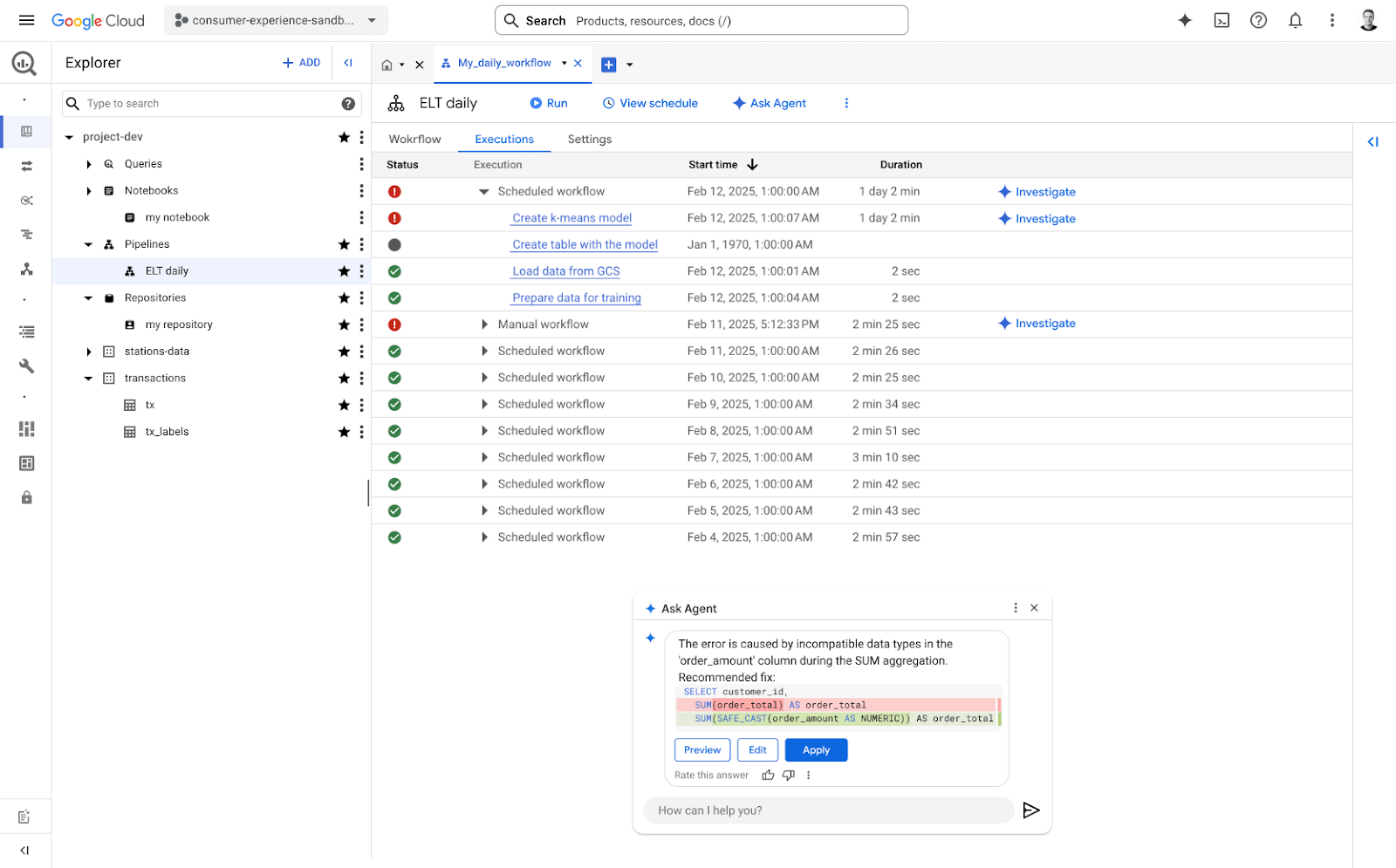
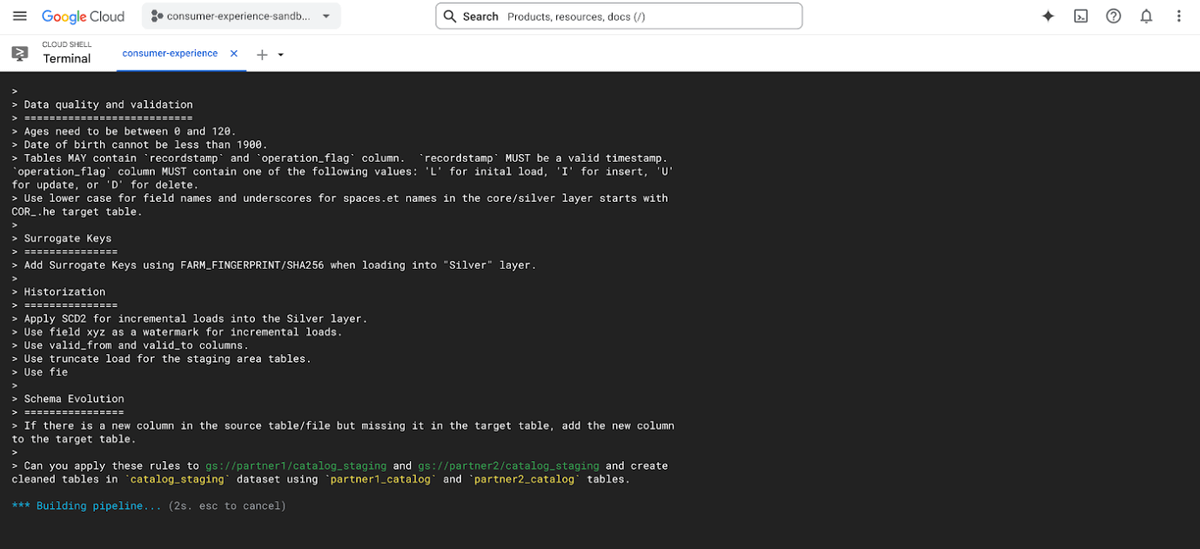
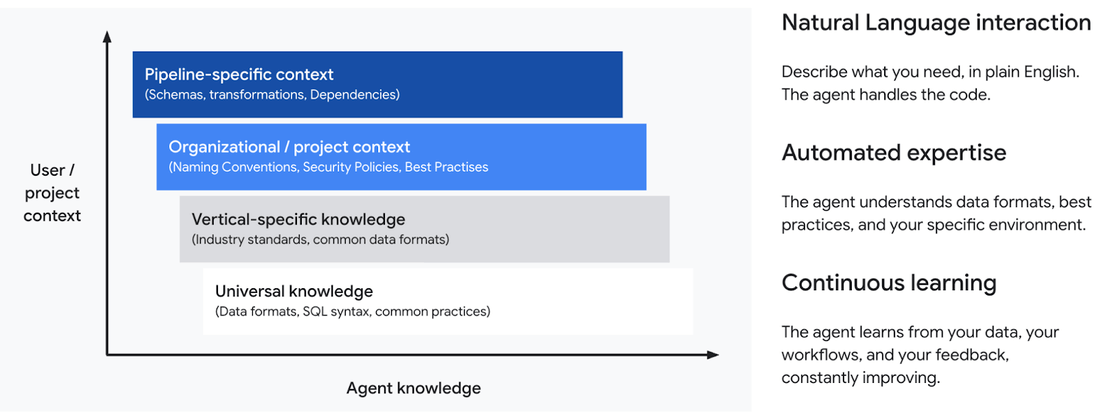
Trong nhiều năm qua, BigQuery luôn là nền tảng hàng đầu của các doanh nghiệp để phân tích, khai thác những insight quan trọng. Tuy nhiên, việc xây dựng, vận hành và khắc phục sự cố các data pipeline luôn là một quy trình phức tạp, tiêu tốn thời gian và nguồn lực chuyên môn. Chính vì vậy, Google Cloud đã ra mắt giải pháp Data Engineering Agent trong BigQuery nhằm đơn giản hóa các tác vụ phức tạp và tối ưu hiệu suất vận hành. Hãy cùng Cloud Ace tìm hiểu nhé.