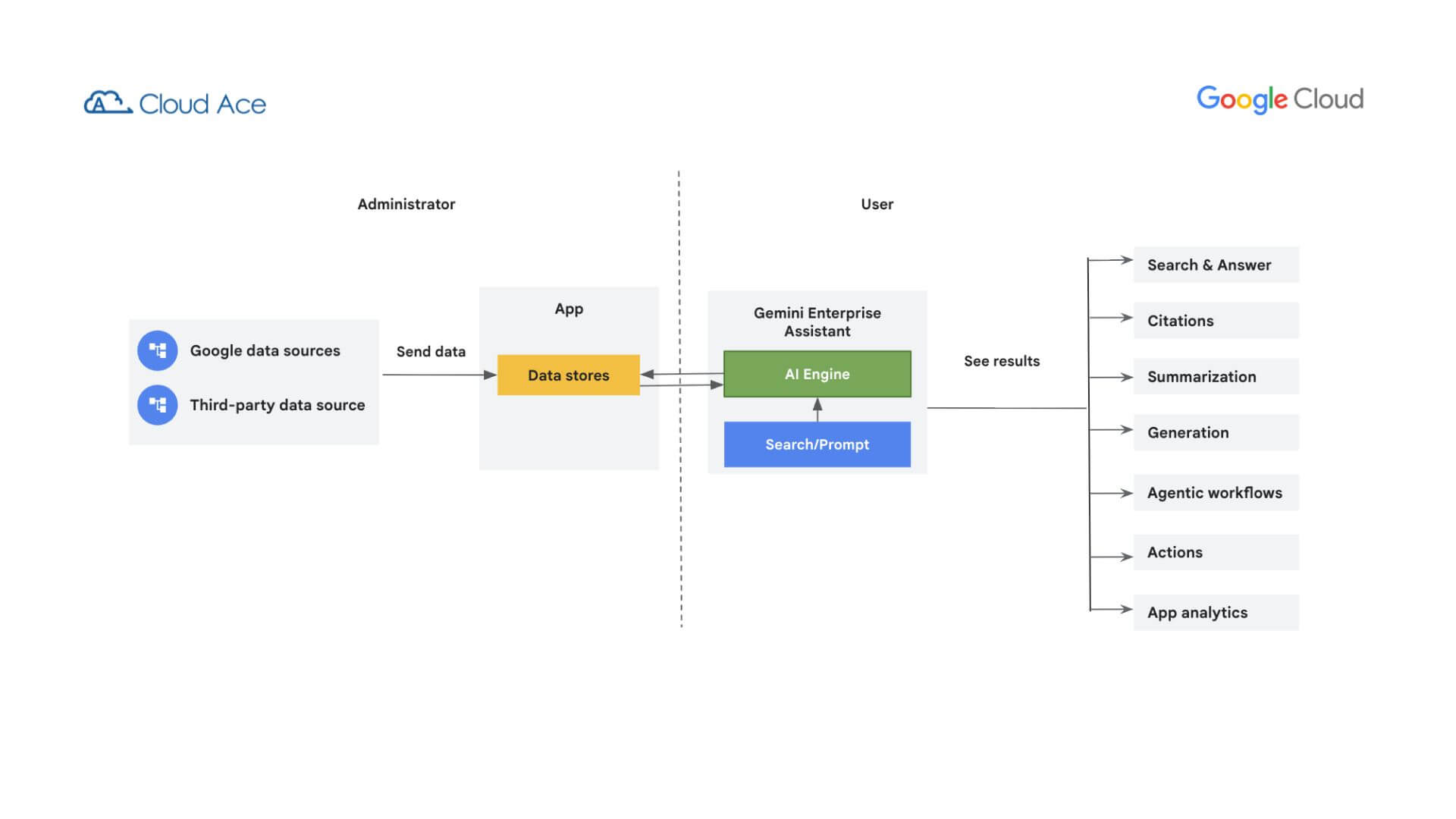
Gemini Enterprise là giải pháp AI toàn diện từ Google, giúp tối ưu hóa quy trình làm việc thông qua việc tự động hóa và hỗ trợ ra quyết định dựa trên dữ liệu thời gian thực. Bằng cách kết hợp Big Data và Machine Learning, hệ thống có khả năng dự báo xu hướng và quản lý rủi ro hiệu quả. Điểm ưu việt của Gemini Enterprise nằm ở khả năng tập trung hóa dữ liệu: Thông qua các trình kết nối (connectors) thông minh, dữ liệu từ Google và các nguồn bên thứ ba được thu thập và lưu trữ đồng bộ. Việc hội tụ nguồn lực thông tin này chính là chìa khóa giúp doanh nghiệp tối ưu hóa khả năng tìm kiếm, phân tích sâu và dự báo chính xác các xu hướng thị trường. Bài viết dưới đây, Cloud Ace sẽ cung cấp cho doanh nghiệp cái nhìn tổng quan về các trình kết nối này.